


Image by Karl Egger from Pixabay
The web, it is fragile.
Several times a day within the work of online seeking of information, my link clicks greet me with the image below. The one I recall most recently was not even that old, it was something published online in 2014.

Another dead link! At least rather than a dead end “not found” message, the Internet Archive Wayback Machine extension (for Chrome and Firefox) at least offers a route to an archived version of a dead link.
The wholesale clear cutting of public web content by, say, Google (e.g. recent closing of Google+) or Wikispaces is one thing I often rail against. But I’ve seen it happen myself at the institutional level from two long term positions of creating web content.
My formative web years, 14 of them, was spent created tens of thousands (or more, no idea how to count) of web sites at the Maricopa Community Colleges, putting our office’s projects online, putting its publications online, putting the outcomes of its events online, putting into place online grant application/review/reporting systems, heck, even a repository.
Every single bit I worked on… is gone. Well, not completely, thanks to the Internet Archive Wayback Machine you can find not only the Maricopa Center for Learning & Instruction’s web site on the day I left (April 6, 2006), but it’s evolution back to 1996, when the Wayback Machine started.
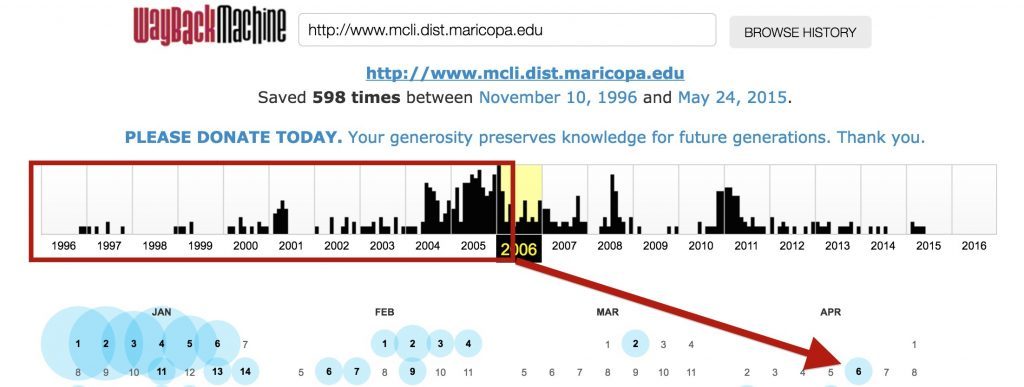
I have my own archive of that web work. I saved all of the source files from the web server, stored on a 40 Gb hard drive.

My 14 years of web work from the Maricopa Community Colleges fit here.
And when I need to refer, link to my past work, I’ve put some of it back online, now hosted in my own domain at http://mcli.cogdogblog.com. The rest of the web, though would likely never find those links (let’s not bemoan too much that we never got the semantic web dreamed of).
Now I certainly would expect my old office would keep the web site built from the late 1990s as their current site. Web sites evolve, but the way nearly all organizations evolve is to pave the new over the old. But when personnel change, when leadership changes, usually the last thing anyone considers is the institutions web history. Like the stream mode of social media, they only think of the present.
There was good reason to get rid of some of my old sites. Some just did not work anymore like the Hero’s Journey Project (wayback link). A number of the sites from the early and mid 1990s worked by having perl scripts write to openly editable text files. There were likely issues with the old wikis that were there. I myself, entering into a technology role with an organization, would put last on my list a desire to keep old technology running.
But digital durability need not be keeping old server code and Flash encrusted sites online, there are more than enough routes to archive dynamic web content in the long lasting format of static HTML. I’ve retired several of my no longer needed WordPress sites as HTML archives, nary a link broken, with of all things, an OSX app called Site Sucker (it comes with a vacuum cleaner icon), itself I assume just a fancy front end for the unix wget commands.
It’s more tedious than complex. And it baffles me that the supposedly most powerful technology company on the planet, while figuring out how to offer an export of my Google+ content as Takeout HTML, could not just save the whole thing as is.
The bulk of my Maricopa was just static HTML, like the Labyrinth-Forum publication from our office (alan’s archive link) or heck, my very first conference presentation about the web published on the web (alan’s archive link).
But institutions pretty much just clear cut their web history.
The same thing happened from my five years with the New Media Consortium (NMC). I joined them in 2006 and revamped their aging site with a new dynamic one, but my first step was archiving the old one (as well as creating archive of two older ones before that). And setting up graceful redirects to manage existing links to older content.
Sometime after I left in 2011, it was mostly slashed and burned. I again left with my own archives, just because I could.
The point here, and I see in threads from the other posts here like Francis Bell’s thoughts on sustainability, that there is a desire for a collective approach to community here that relies as well on a distributed approach to where “stuff lives” :
One practical manifestation of sustainable practices is authors cross-posting on femedtech.net and their personal blogs.
My wee bit of research finds the idea of Individualist Feminism:
Individualist Feminism, sometimes called Libertarian Feminism or ifeminism, is a term for feminists whose emphasis is on individualism, particularly from the state, from the patriarchy, and from any kind of hierarchy.
I’m not thinking as much of making a case of the individual versus the collective, or hierarchy. But beyond a few exceptions (likely there are more), for the most part I see the durability of open digital content being more sure in the hands of the individuals who create them, rather then the organizations/institutions they are made for.
And I think organizations / institutions, despite noble mission statements, are rarely thinking about their digital legacy.
Is this off base? Or maybe I lean too much on my “individual” experience. But I care very deeply about the longer term durability of all we are doing in the name of open.
And I grow tired of confronting “not found” messages.
Drawn a bit from a 2016 blog post "Digital Durability? My Money is on the Individual" https://cogdogblog.com/2016/04/digital-durability/

Provide Feedback